2024年4月,李飞飞在 TED 大会上发表了一场演讲,标题是《With Spatial Intelligence, AI Will Understand the Real World》。在演讲的开头,她没有直接谈技术,而是展示了一张全黑的图片。
"我要给你们看一个什么都没有的世界,"她说。
这是5.4亿年前的地球。彼时生命形式极其简单,大部分生物漂浮在海洋中,没有眼睛,不知道光的存在,也没有方向感。然后——寒武纪来了。
大约5.4亿年前,第一批拥有视觉的生物出现了。眼睛的诞生彻底改变了进化的游戏规则:生物开始主动寻找食物、躲避捕食者、建立空间关系。捕食者和猎物之间的"军备竞赛"推动了寒武纪生命大爆发,今天几乎所有主要动物门类都在这一时期出现。
"宇宙开端,一片黑暗,"李飞飞在演讲中说,"直到第一批生物发展出了视觉,引爆了生命、学习和进步的大爆发。"
她认为,AI 和机器人正在经历一个类似的时刻。
李飞飞是谁?
如果不熟悉这个名字,简单介绍一下:
李飞飞是斯坦福大学计算机科学教授、斯坦福人类中心 AI 研究所(Stanford HAI)的创始主任。她在 AI 领域最著名的贡献是创建了 ImageNet——一个包含超过1400万张标注图像的大规模数据集,直接推动了深度学习在计算机视觉领域的突破。
她被称为"AI 教母"(Godmother of AI),不仅因为 ImageNet,更因为她长期倡导 AI 应该是增强人类能力、造福人类的工具,而非替代人类的威胁。
2023年,她出版了自传《The Worlds I See》。2024年,她创立了 AI 公司 World Labs,专注于空间智能的研发。2025年,她在 Y Combinator AI Startup School 发表了关于空间智能的系统性阐述。
空间智能是什么?
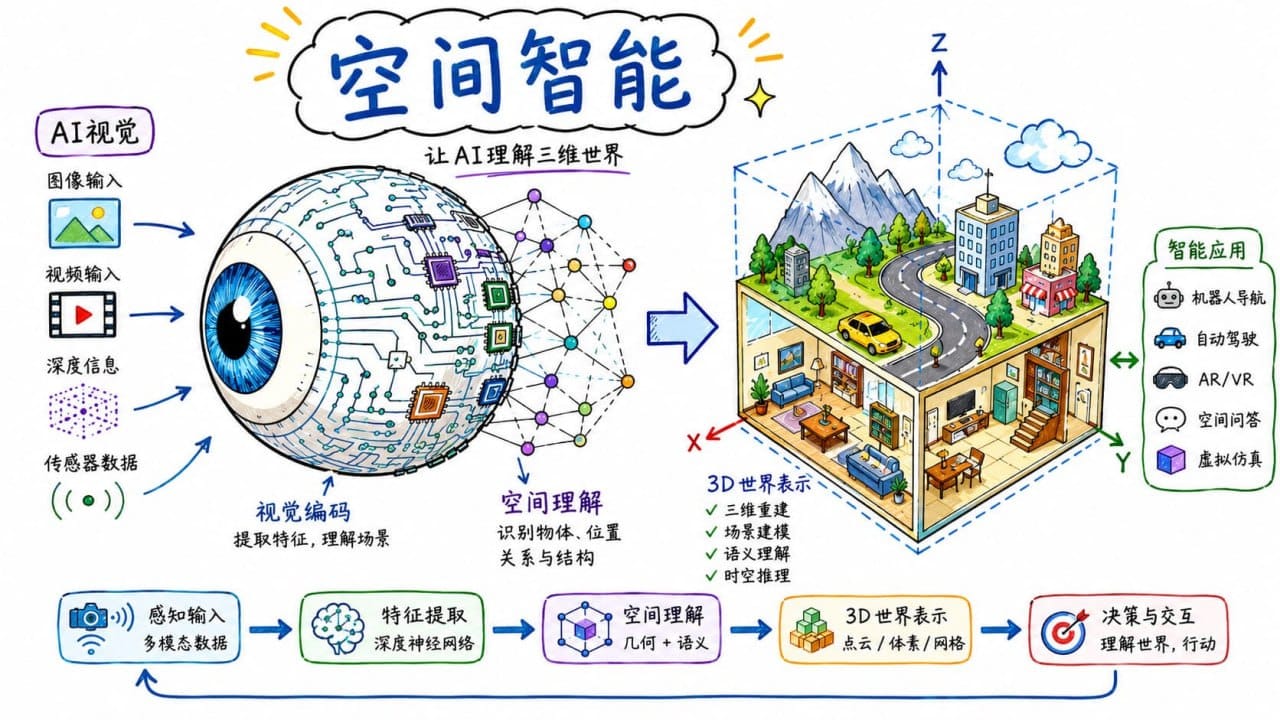
空间智能(Spatial Intelligence) 是李飞飞提出的一个概念框架,指 AI 系统从观察和理解二维图像/视频,进化到能够感知、推理、生成和交互三维物理世界的能力。
这不仅仅是"看得更清楚",而是:
- 感知(Perceive):理解场景中物体的空间位置、深度、关系
- 生成(Generate):从文本、图像、视频创建可信的三维世界
- 推理(Reason):理解物理世界的规律——重力、碰撞、因果
- 交互(Interact):在三维空间中行动、导航、改变
用她自己的话说:
"空间智能将视觉转化为行动,将理解转化为推理,将想象转化为创造。"
这不是一个纯学术的概念。World Labs 已经把它变成了可用的产品。
World Labs:空间智能的商业化
2024年,李飞飞创立了 World Labs,定位是"spatial intelligence company"。
官方网站的描述非常清晰:
World Labs is building the next frontier of generative AI — one where models can understand and interact with the world to empower use cases from storytelling to simulation.
他们的第一款产品叫 Marble(大理石),功能是:从文本、图像、视频或360°全景图,生成空间一致、高保真、可持续的三维世界。
具体能力包括:
- 多模态输入:用文字、图片、视频或全景图创建详细的三维世界
- 3D布局控制:精确控制生成世界的三维布局
- 交互式编辑:调整特定元素或重塑整个三维世界
- 扩展与合并:将生成的世界扩展、编辑、合并,构建更大更沉浸的环境
- 多格式导出:下载并以各种2D和3D格式导出,融入现有工作流
这些能力指向的应用场景包括:
- 艺术/电影/VFX/虚拟制作:概念设计到电影级视觉效果的完整创意流程
- 游戏/AR/VR/沉浸式媒体:创建可进入、可探索、可交互的虚拟世界
- 机器人/建筑与设计/健康系统:模拟运动、物理规律和智能环境
在2026年3月的一篇博客文章《3D as Code》中,World Labs 写道:
文本成为了软件的通用界面;3D正在成为空间的通用界面。它是一种让人类和 AI 系统能够共同生成、编辑、模拟和分享世界的媒介。
这揭示了更宏大的愿景:让 3D 创作变得像写代码一样可组合、可版本控制、可分享。
为什么是现在?
理解空间智能为什么在这个时候爆发,需要一点技术背景。
过去十年,AI 在语言和图像理解上取得了巨大进步。大语言模型(LLM)让机器能够理解和生成文本,Diffusion 模型(如 DALL-E、Stable Diffusion)让 AI 能够生成逼真的图像和视频。
但这些模型有一个根本的局限:它们处理的是像素的统计分布,而不是物理的三维现实。
一个 DALL-E 生成的人像照片,看起来很真实,但从任何角度去看都还是同一张2D图像。视频生成模型可以创作流畅的运动画面,但画面中的物体不会遵守物理定律——一个从高处落下的物体可能会"飘走"而不是坠落。
二维表示 vs 三维理解,这是本质的区别。
我们的物理世界是三维的。人类大脑在处理视觉信息时,会自动构建三维的心理模型——我们不仅"看到"了一张图片,还"知道"物体在哪里、有多大、相互之间什么关系、下一秒可能会发生什么。
这种能力对于 AI 在真实物理世界中运作至关重要。无论是自动驾驶、机器人操作,还是 AR/VR 应用,都需要 AI 能够理解和推理三维空间。
与大语言模型的关系
这里需要厘清一个常见的误解:空间智能不是在"对抗"或"取代"大语言模型。
李飞飞在多个场合都明确表示:AI 不仅仅是 LLM。
大语言模型擅长处理序列化的符号信息——文本、代码、对话。但它们缺乏对物理世界的直觉理解。
举个例子:你可以用 LLM 写一篇关于"把水倒进杯子"的详细步骤说明,但 LLM 并不知道水是什么质感、杯子拿起是什么手感、倾斜角度多少水会洒出来。
空间智能补全了 AI 理解物理世界的这一块拼图。
两者不是竞争关系,而是互补关系。World Labs 的模型可以接收文本指令("创建一个日式庭院"),生成三维世界——这正是语言理解和空间生成的结合。
技术挑战
为什么空间智能比语言智能更难?
李飞飞在 Y Combinator 的采访中提到过几个关键挑战:
1. 数据的三维性
训练语言模型可以用互联网上的大量文本,但三维世界的标注数据远远更少。World Labs 需要自己创建或采集高质量的三维数据。
2. 算力和效率
三维场景的计算量远大于二维图像。实时渲染、可编辑的三维世界需要巨大的算力支持。
3. 物理规律的建模
让 AI 理解重力、摩擦、碰撞、弹性、光照变化等物理规律,是一个尚未完全解决的问题。
4. 时序一致性
视频生成中常见的问题是时间不一致——物体可能突然消失或变形。三维世界的时序一致性更加复杂。
空间智能的意义
如果说语言模型让 AI 学会了"思考"(处理抽象符号),空间智能则让 AI 学会了"行动"(在物理世界中运作)。
一个能生成三维世界的 AI,意味着什么?
对于创意产业:设计师和艺术家可以用自然语言创建和迭代三维场景,大幅缩短从概念到成品的时间。电影制作人可以用它构建虚拟场景, 游戏开发者可以用它快速生成游戏世界。
对于机器人产业:当前的机器人需要针对每个具体任务进行大量编程和调试。如果 AI 能够理解三维空间和物理规律,机器人就可以接受更高层次的指令——"去厨房给我拿一杯水"——而不是"向左移动23厘米,旋转15度,抓取……"
对于科学研究:模拟真实的物理环境对于药物发现、材料科学、气候建模等领域都有巨大价值。
对于人类自身:理解空间智能的概念,也让我们重新审视自己的智能。我们的视觉系统经过数亿年进化才达到今天的水平;而 AI 在短短几十年里就走过了类似的路——这个过程本身就值得深思。
寒武纪的隐喻
回到 TED 演讲的核心隐喻。
5.4亿年前,视觉的出现不仅让生物"看得见",更让它们能够主动与周围环境互动——捕食、逃避、构建领地、建立社会关系。这是智能的一次根本性跃迁。
AI 正在经历类似的时刻。
过去的 AI 模型——无论是图像分类还是语言生成——本质上都是被动的:它们处理输入,产生输出,但并不真正"存在于"这个物理世界中。
空间智能让 AI 主动参与三维物理世界。这不仅仅是能力边界的扩展,更是 AI 存在形态的一次质变。
当然,这里面也有值得警惕的地方。AI 进入物理世界意味着更大的影响力和更大的风险——机器人、自动化武器、深度伪造的三维环境……这些应用都需要认真思考伦理和安全问题。
李飞飞在演讲的最后说了一句话:
我们正在赋予 AI 一双新的"眼睛",而这双眼睛看到的世界,将比任何人曾经想象的都要宽广。
这或许有些诗意。但考虑到她过去二十年在 AI 领域的轨迹——从 ImageNet 到斯坦福 HAI 再到 World Labs——她说的"宽广",可能真的在不远处等着我们。
参考来源:
- TED2024: "With spatial intelligence, AI will understand the real world" — Fei-Fei Li
- Y Combinator AI Startup School (June 2025): "Spatial Intelligence is the Next Frontier in AI" — Fei-Fei Li
- World Labs 官网: www.worldlabs.ai
- Stanford HAI: "Spatial Intelligence Is AI's Next Frontier" (TIME, December 2025)
- 《The Worlds I See: Curiosity, Exploration, and Discovery at the Dawn of AI》— Fei-Fei Li (2023)